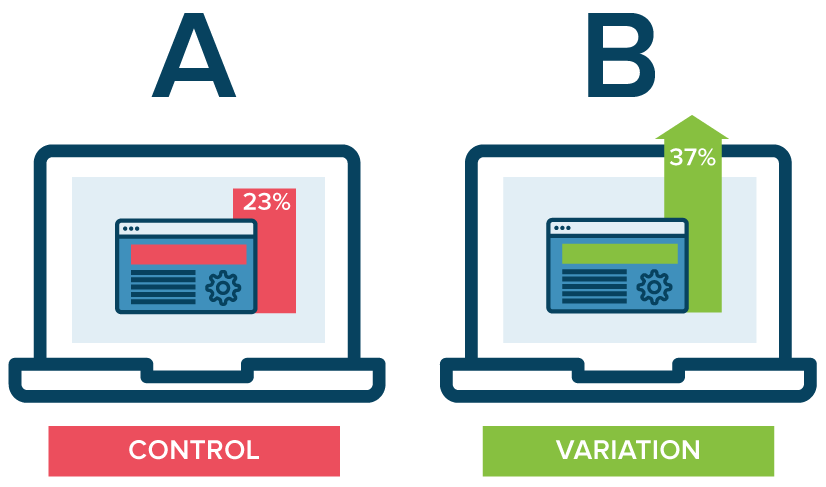
Reading-Amazin
Open the website
 , Open the Github
, Open the Github
This is the side project about bookstore e-commerce website, which replicates the industry use case.
I was the team leader, who was responsible for conducting research on the technology,
and participated in the whole software development process from design to implementation and delivery.
I developed software functionalities to ensure the user journey is not interrupted.
Collaborating with peers to perform error analysis and make improvements based on feedback.
The technologies included: HTML, CSS, JS, C#, Entity Framework Core, Microsoft SQL Server.